Understanding Customer Reviews using NLP

Understanding Customer Reviews using NLP
Listening to the voice of the customer is important to any business, as it helps identify potential issues. Nowadays most businesses have an online presence both in terms of a website and social networks. This provides a platform for customers to voice their opinion through written comments. NLP can be used as a valuable tool to analyze and monitor customer comments at scale.
In this post we will cover key concepts of NLP and as they relate to sentiment analysis. We are going to see how NLP can be used to analyze natural language and determine customer's attitude. There is value in knowing your customer. Value in fixing what is broken and value in discovering new opportunities.
What is NLP
The acronym NLP stands for Natural Language Processing. NLP is a discipline of computer science whose goal is to produce computing machines that could process and understand human language. How the human language stacks up against existing computer languages is shown in this diagram named The Chomsky-Schutzenberger Hierarchy after two of the greatest linguists of our time.
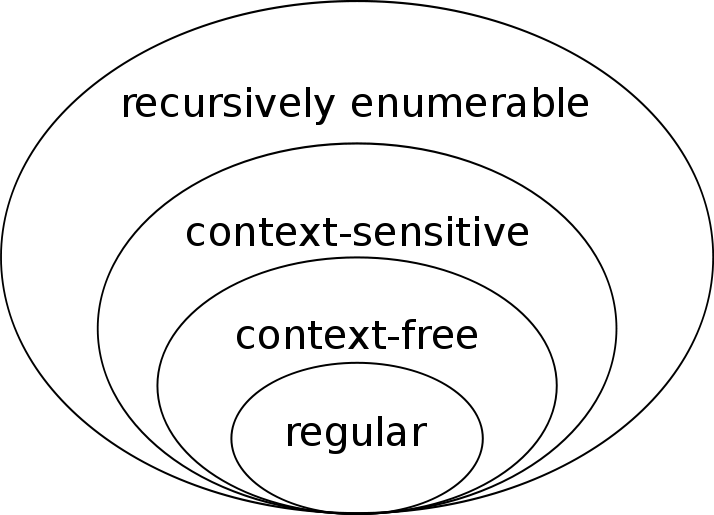
Finite state automata such as regular expression matcher or Viterbi decoder (used in wireless and wired communication protocols) belong to a class of regular language decoders. Computer languages are mostly context free with C++ having some context dependent features making it already "difficult". The human languages are context sensitive and beyond.
It cannot be overstated how important language is to human intelligence. In fact, one definition of full Artificial Intelligence is the Turing Test. By this definition full artificial intelligence will be attained when a human being, sitting behind a computer console and chatting with a peer, cannot tell if the peer is a machine or another human. At the moment there is some hype around deep learning but once the dust settles it will be a while longer until we create machines with full command of human language and reasoning.
There are four broad areas of NLP with inherent applications and problems:
- Speech recognition and synthesis
- Syntax
- Semantics
- Discourse
Speech recognition and synthesis are low level signal processing tasks. Their aim is to covert audio waveforms into sequence of words/phonemes or vice versa. Both tasks are much improved if you can employ domain knowledge gained from the other NLP layers.
Syntax deals with the structure of language. It defines the structure of a word and a sentence, breaks up text into sentences and words, assigns classes or part of speech to words and analyzes sentences using grammar rules. If you ever used a spell checker in Microsoft Word you have benefited from NLP syntax analysis.
Semantics is the next step trying to extract meaning. If your just look closer you will find ambiguity in any language. In Bosnian word "mina" is a female name, explosive device or a mining pit, in German word "Hahn" is a rooster or water tap. As you can see before you can extract meaning you have to resolve ambiguity using context. If you get semantics right it opens up doors to applications such as:
- machine translation
- automatic text generation
- sentiment analysis
- topic recognition
Finally discourse, as you might guess, deals with using all of the NLP methods to conduct or summarize an entire conversation. It opens up and explores even the possibility to reason about concepts, draw novel conclusions and articulate them.
In short a true AI system would have full command of up to and including discourse.
Sentiment Analysis Explained
For this article we are going to look closer at Sentiment Analysis. The goal of sentiment analysis is to determine the emotion or attitude expressed in a comment or review. Plainly put:
- input is: comment on or review about a product or service or any other topic
- output is: emotional state such as positive/happy, negative/sad or neutral
Please notice something very obvious, very important and easily overlooked: To get the sentiment you have to have a customer that either likes you or hates you. If your customer does not care to leave feedback you will have nothing to analyze. Your problem is then far bigger than sentiment analysis: their indifference implies your irrelevance but I digress.
Available approaches are knowledge based or based either on statistical methods and chief among them machine learning methods. The first approach uses grammar rules and manually encoded domain knowledge.
Knowledge based approach might be able to uncover sentiment that is subtle, expressed indirectly. On the other hand machine learning methods benefit from the numerous corpora of tweets and comments available on social networks. Often these comments are tagged and so we know upfront their sentiment. Using them in large amounts allows for statistical models that can uncover proper correlations and will work well on novel, unseen input. Of course the two approaches can be combined. For example just splitting a comment into a bag of words and training a model will not capture linguistic relations that well. An approach where text is parsed using grammar rules and then trained using both words and sentence structure could give us better results. I emphasize "could" because classification also depends on selecting the right model. If a model is selected that is unable to properly distinguish or separate input into different categories then input will be put into the wrong category and give us incorrect results.
One issue with knowledge based methods is their manual nature. You need someone to manually encode knowledge and that becomes expensive. So currently most activity happens on statistical side using machine learning methods to consume large amounts of data and hopefully uncover all that is relevant.
Following illustration shows what a machine learning algorithm does:
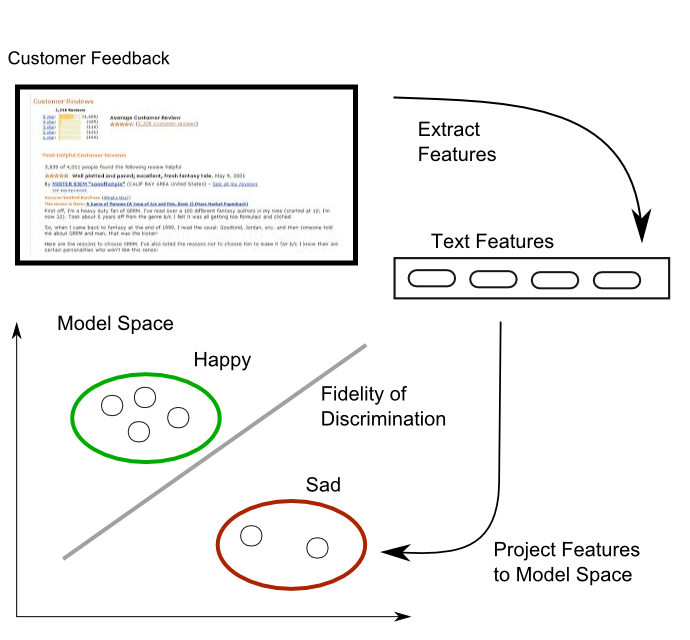
First step in the process is to extract relevant features. As most machine learning algorithms expect well conditioned numeric values this first step is far from trivial. We have to somehow extract numeric features from text and characters. To that end various encoding schemes have been developed. Two very famous encodings are word2vec and doc2vec. Next features are projected into a space where the model lives. The machine learning model is not just the shape of the green/happy or red/sad categories. It is also the dimension and topology of the space in which the categories exist. If the model is not selected properly the two categories will overlap. Model fidelity or capacity to discriminate/distinguish will not be 100% and if it drops below 50% then throwing a dice will give you better results.
On top of the issue of model selection we mentioned before that human language is ambiguous. In fact positive/negative sentiment is a human and very subjective qualification. For example smiling in heterogeneous cultures is more common because it serves as a bridge (due to the variety of backgrounds) while in more homogeneous societies too much smiling is considered suspicious, even dishonest. A case in point is Walmart's attempt to penetrate German market. It probably failed for several reasons but one theory puts some blame on a misplaced customer engagement model. Germany is far from being a homogeneous country but like any European country it is nowhere near as heterogeneous as the USA. Apparently Walmart copied the USA engagement model and it did not do well in Germany [1].
Provisioning Standford CoreNLP
Ref: https://nlp.stanford.edu/sentiment/
Initially we tried to use IBM Watson for NLP processing. For that you need an account with IBM Bluemix. If you sign up for a free account you get the most basic services and you have to manually login to keep them from shutting down after a period. On top of that Watson NLP is based on a model trained on a large corpus of Twitter data but does not expose many of the additional NLP methods such as language and grammer models.
All of that is available with Standford CoreNLP. The NLP research group at Stanford has developed a java library implementing almost all stages of natural language processing. Among the components is also a sentiment analyzer. For an overview and instruction on how to setup development environment you can see their website.
Once environment is set up basic usage of Stanford CoreNLP library is illustrated in the following code snippet:
public static void main(String[] args) throws IOException {
Properties props = new Properties();
props.setProperty("annotators", "tokenize, ssplit, pos, lemma, ner, parse, dcoref, sentiment");
StanfordCoreNLP pipeline = new StanfordCoreNLP(props);
// Initialize an Annotation with some text to be annotated. The text is the argument to the constructor.
Annotation doc = new Annotation("Kosgi Santosh sent an email to Stanford University. He didn't get a reply.");
pipeline.annotate(doc);
List sentences = annotation.get(CoreAnnotations.SentencesAnnotation.class);
for(CoreMap sentence: sentences) {
// traversing the words in the current sentence
// a CoreLabel is a CoreMap with additional token-specific methods
for (CoreLabel token: sentence.get(TokensAnnotation.class)) {
// TODO: Do something at word or sentence level
}
}
}
Just in case you are not familiar with Java the above code first creates a pipeline object configured to generate several bits of information such as annotations, part of speech, lemmatization etc. Then sample input text is defined and passed into the pipeline. Finally the pipeline is queried over all sentences and words within sentences to print out or otherwise process parsed annotations.
Internals of Sentiment Analysis
StanfordNLP uses Recursive Neural Tensor Network (RNTN) model trained on their own parse trees data set called Stanford Sentiment Treebank (https://nlp.stanford.edu/sentiment/treebank.html). Treebank data set is based on existing dataset introduced by Pang and Lee and contains 11855 sentences extracted from movie reviews and was parsed with Stanford Parser [2]. An example of one of their treebank for sentence: "A poignant, artfully crafted meditation on morality.", is shown below:
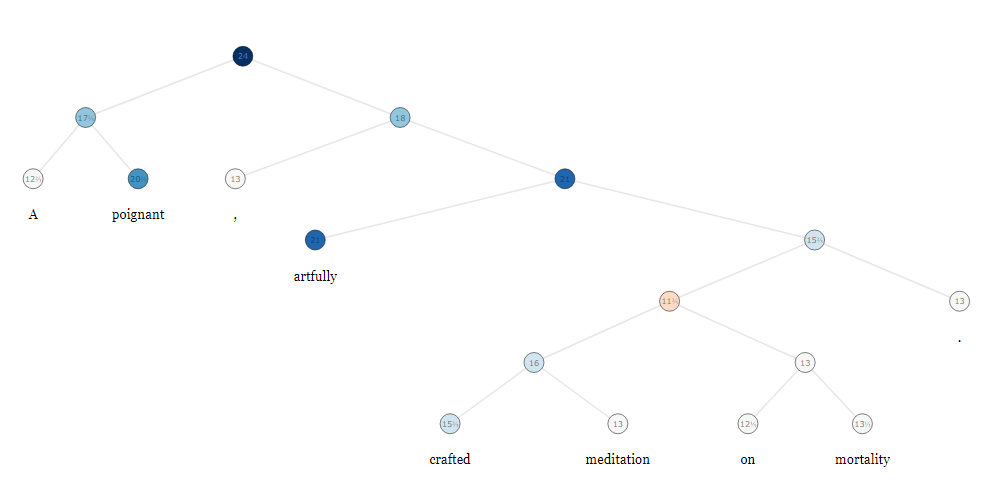
As part of the parsing process, Stanford parser uses the Penn Treebank Parts-Of-Speech (POS) tagset containing 36 tags and 12 tags for punctuation and currency symbols.[8]
POS tags table is shown below:
| Tag | Description | Tag | Description |
|---|---|---|---|
| CC | Coordinating conjunction | TO | Infinitival to |
| CD | Cardinal number | UH | Interjection |
| DT | Determiner | VB | Verb, base form |
| EX | Existential there | VBD | Verb, past tense |
| FW | Foreign word | VBG | Verb, gerund/present pple |
| IN | Preposition | VBN | Verb, past participle |
| JJ | Adjective | VBP | Verb, non-3rd ps. sg. present |
| JJR | Adjective, comparative | VBZ | Verb, 3rd ps. sg. present |
| JJS | Adjective, superlative | WDT | Wh-determiner |
| LS | List item marker | WP | Wh-pronoun |
| MD | Modal | WP$ | Possessive wh-pronoun |
| NN | Noun, singular or mass | WRB | Wh-adverb |
| NNS | Noun, plural | # | Pound sign |
| NNP | Proper noun, singular | $ | Dollar sign |
| NNPS | Proper noun, plural | . | Sentence-final punctuation |
| PDT | Predeterminer | , | Comma |
| POS | Possessive ending | : | Colon, semi-colon |
| PRP | Personal pronoun | ( | Left bracket character |
| PP$ | Possessive pronoun | ) | Right bracket character |
| RB | Adverb | " | Straight double quote |
| RBR | Adverb, comparative | ´ | Left open single quote |
| RBS | Adverb, superlative | ´´ | Left open double quote |
| RP | Particle | ` | Right open single quote |
| SYM | Symbol | `` | Right open double quote |
RNTN network consists of a pretty simple structure, two leaf nodes (children), a root node and a softmax classifier. Two child nodes are connected to a single root node and will receive input word (out of full input sentence) or phrase vectors, and the root node will output the resulting phrase vector which can then go as input to a leaf node along with the next word in the sentence. The process is repeated until, at top top level root node, we get a full sentence vector (on the image below, that'd be the p2 node).
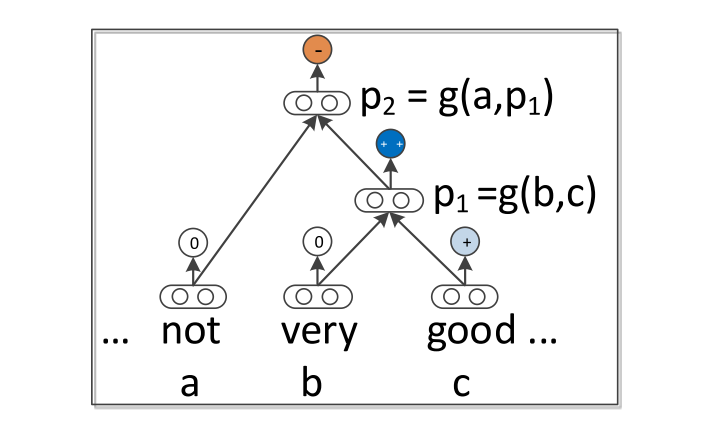
The network, in general works as follows:
- For the input sentence, the sentence is parsed into a binary tree (using the Stanford Parser) and each word is represented as a vector which has many things encoded in it, word similarity being one of them.
- A parent vector (p1 or p2 in the image) is calculated from a pair of word vectors or a word and previous parent vector (p1 in the image). This way we get a phrase vector
- In case of sentiment analysis, the network also features softmax classifier on top of the root node which will, as a result, give an overall sentiment/class of given word/phrase or sentence.
The structure can be seen in image below [8]
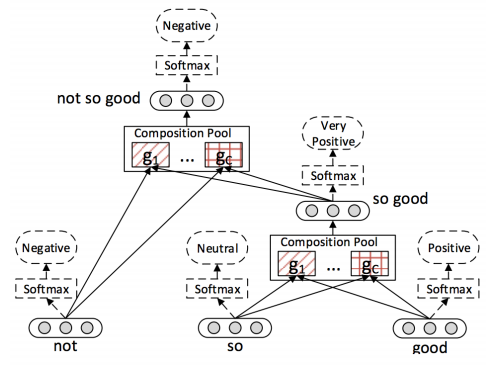
As the illustration shows sentiment result is computed initially on each word and then results are propagated upward until full sentence is analyzed. For our needs, and that is to process customer reviews, we have a bit more work left to do. Namely we will obtain sentiment estimates for each sentence of the review. Now the question is how to combine this result into a definitive answer.
Consuming Sentiment Analysis
StanfordNLP will work only on individual sentences, meaning that if you have a whole paragraph that represents a review you can only do sentiment analysis on its individual sentences. Now, in order to get a sentiment of the paragraph, you'd need to get sentiment for each sentence and use one of the following ways to combine results:
- Average sentiment of all sentences since a sentiment of a sentence is nothing but a number in certain range, we can calculate average over all sentences.
- Weighted average of sentences. Add weight to each sentence based on its importance, ie. perhaps in a review first sentence should have more weight if we assume a user will first give its overall impressions and then elaborate after.
- User optimistic/pessimistic approach by taking either highest or lowest sentiment respectively and use that as the overall sentiment of a paragraph.
- Averaging positive aspects, average negative aspects, and take the maximum absolute value of either positive or negative, and reduce it by a factor of the value for the opposite sentiment. So 10 minor negative sentiments could be outweighed by 2 extremely positive one.[1]
In general, results of the sentiment analysis are used to determine general public's interest in certain topics. For example it can be used to analyze what's the overall sentiment towards a certain presidential candidate, product, movie, song, etc. This information can then be used to, hopefully, improve the aforementioned things. A person or a company can then decide to use the information gathered in some larger analytical systems and/or simply present the data to general public.
Information is often presented in "visually impactful way" [9] which can often include
- graphs,
- charts,
- spark lines.
Additionally, sentiment can be represented in timeline so one can observe the changes over some period. Presentation can also include things like emojis where each sentiment rating is assigned to a specific emoji ranging from unhappy to happy emoji, or something similar and appropriate for the context. Here is an example of a visual presentation [9]:
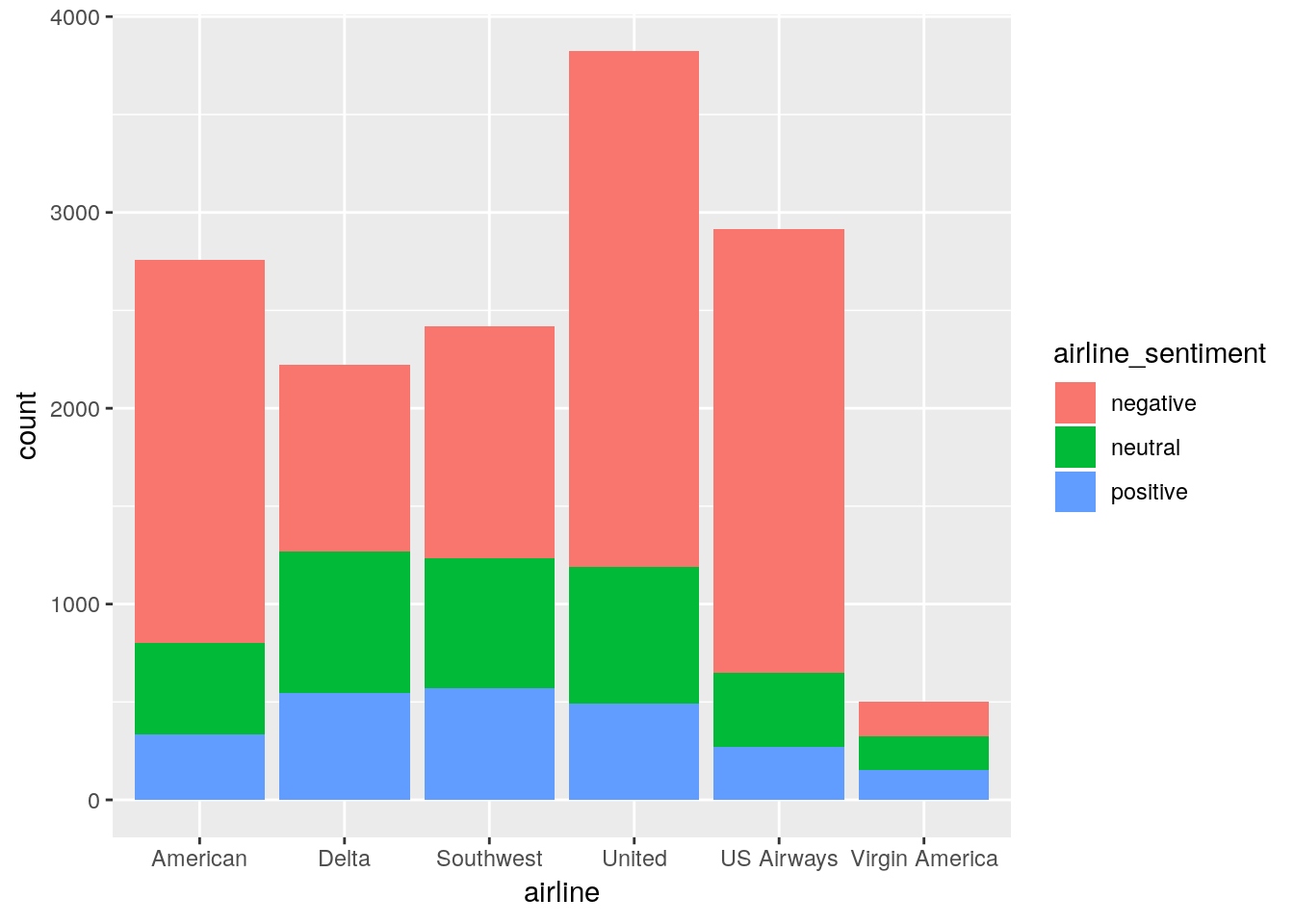
Conclusion
Current models work pretty well in almost perfect conditions, however, they're still far from truly interpreting language in a way humans do, instead they often take inputs at face value. Nevertheless, we work with what we have, and that's an imperfect system whose results can't and shouldn't be taken as something that's 100% correct and should be instead often validated using some concrete data. For example, scoring system in reviews can help when validating a model during the training phase.
As mentioned, the system is not perfect so here are some shortcomings we observe when it comes to sentiment analysis:
- The (not so) obvious factors
- lack of capitalization (if used for named entity resolution)
- poor spelling will force usage of fuzzy or approximate word matching leading to combinatoric issues
- poor punctuation will break tokenizer functionality
- poor grammar will break parser functionality[7]
- Sentiment detection will work best if analyzed text is grammatically and syntactically same as the dataset the model is trained on.
- For example, basic Stanford CoreNLP model is trained on dataset which consists of thousands of movie reviews, analyzing "Macbeth" wouldn't lead to precise results and it's questionable if results would be usable at all.
- Sarcasm is not detectable without training a new model on a large corpus of sarcastic statements.
- In case of a product reviews, sentiment analysis should be done in the context of the product. For example, if a review states that a product is not working, or is too expensive, that should be treated as a negative sentiment, not a neutral one as is the case at the moment.
- Using pronouns in the analysis should take the context into account. In the case of, let's say a camera, by default "It's perfect" will be treated as a Neutral sentiment, however, "Camera is perfect" is treated as Positive, even though, both reviews are describing the same item.
- Same sentence with different subjects can have different sentiments which can be seen here: https://stackoverflow.com/questions/42027119/stanford-nlp-sentiment-ambiguous-result
- Relative sentiment: is not a classic negative, but can be a negative nonetheless. Example: “I bought an iPhone” is good for Apple, but not for Nokia.
- Ambiguous negative words: Their context needs to be thoroughly understood and tagged accordingly. Example: “That backflip was so sick” is really a positive statement.
Our Demo
We have put together a demo to showcase sentiment analysis using Stanford NLP. It is a simple webpage that receives a block of text and outputs per sentence analysis. Please check it out at:
References
https://gist.github.com/shagunsodhani/6ca136088f58d24f7b08056ec8b97595
https://www.aclweb.org/mirror/emnlp2016/tutorials/zhang-vo-t4.pdf
https://www.marketmotive.com/blog/discipline-specific/social-media/sentiment-analysis-article
https://www.kaggle.com/shaliniyaramada/visualization-and-sentiment-analysis
https://stackoverflow.com/questions/7597061/add-a-language-in-the-stanford-parser
